
Search Consoleからの通知メール
Search Consoleから届いたメールは以下のようなもの。「送信されたURLにnoindexタグが追加されています」とあります。何かのURLにnoindexタグが入っていたので、Googleさんが情報を読みに行けなかったようです。
とりあえず、「Search Consoleを使用してインデックスカバレッジ件の問題を修正」というボタンを押してみることに。
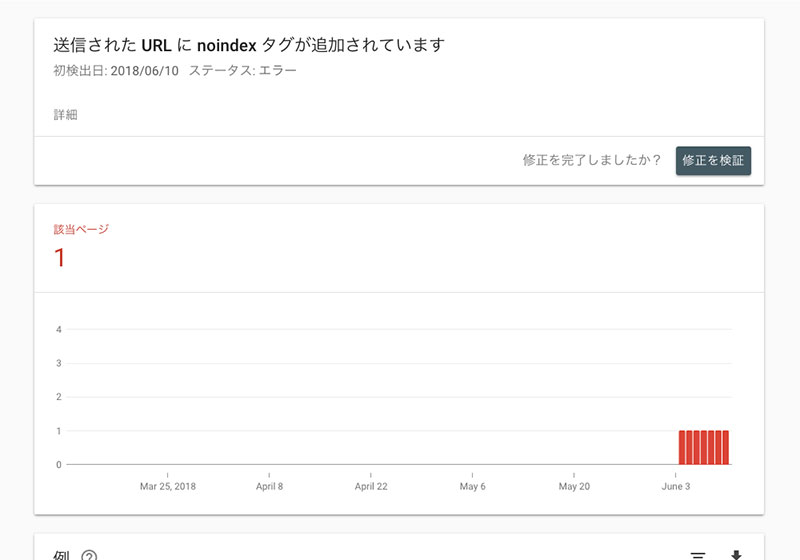
Search Consoleのインデック スカバレッジ画面
Search Consoleの「インデックス カバレッジ」ページに飛ぶと、何やら数日前からエラーが1件出ているのがわかりますね。
下にスクロールすると、どうやら以前に書いた記事にエラーが出ているようです。
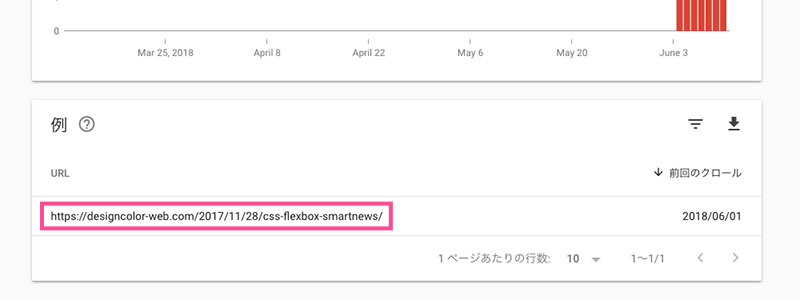
ちなみに該当の記事はこちら。
Flexboxでスマートニュース(SmartNews)風のレイアウトを実装する方法 | Design Color
そもそもnoindexとは
noindexとはGoogleの検索結果に表示されないようにする設定のことです。metaタグに以下のように記載することで、クローラーに「このページは読みにこなくて結構です」と教えてあげるわけですね。
<meta name="robots" content="noindex">そういう設定があるならば、エラーではないのでは?と思いますよね…。ですが、おそらくエラーが出たということは、「XMLサイトマップは送信されているのにも関わらず」という点がポイントになってくると思います。
XMLサイトマップとは
XMLサイトマップとはサイト内のURLや更新日などを集約させたファイルで、クローラーがサイトを読み取るための地図のような働きをします。
基本的にWordpressでもなんでも、ひとつ記事を書いたら自動的にXMLサイトマップに情報が追加されてGoogleへ送信されるため、クローラーはそれを頼りにサイトへ情報を読み取りにきます。
ここでもし、クローラーが読み取りにきた記事にnoindexがついていたならば、「XMLサイトマップには情報があったのに、いざクローラーが読み取りにきたらnoindexだった」という矛盾した状況になってしまいますよね。なので、もし記事にnoindexをつけたなら、XMLサイトマップからはその記事を除外するという手順を踏む必要があるのです。
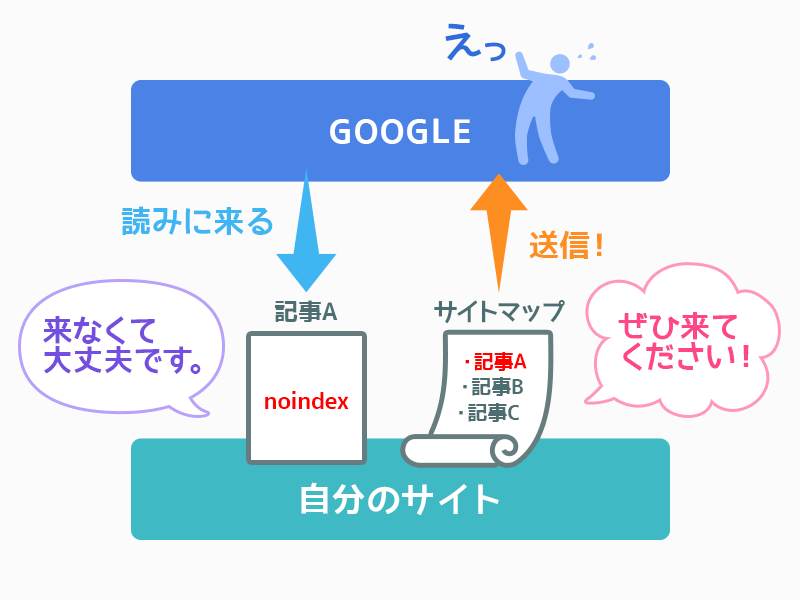
【だがしかし】記事にnoindexをつけた覚えはない
自身でnoindexをつけた覚えがあるならば、XMLサイトマップからページを削除すれば解決ですが、今回のケースはそうもいきません。なぜなら、私は書いた記事をnoindexにしていないのです。
実際に、該当ページのソースを確認してみても、やはりnoindexはついていませんでした。

とりあえずひとつひとつ原因を探ろう
robots.txtを確認
エラーが出ている該当URLをクリックすると、右にバーが現れます。ここで原因を探っていくことに。「ROBOTS.TXTによるブロックをテスト」を押してrobots.txtの状態を見てみましょう。
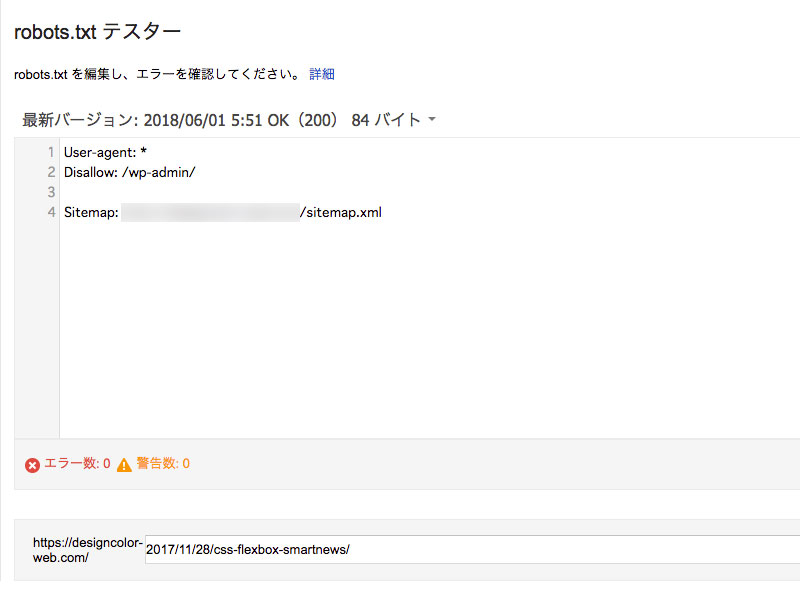
noindexの他に検索結果に表示させないようにするには、robots.txtに記載するという方法もあります。noindexは「インデックスをしなくていい」という設定ですが、robots.txtの設定はもっと拒否の度合いが強く、「クローラーのアクセス自体を拒否する」時に使います。
ですが、こんなところにそんな設定を書くはずもなく…、robots.txtにエラーは出ていないようです。
検索結果を確認
次に3番目の「検索結果として表示」を押してみます。
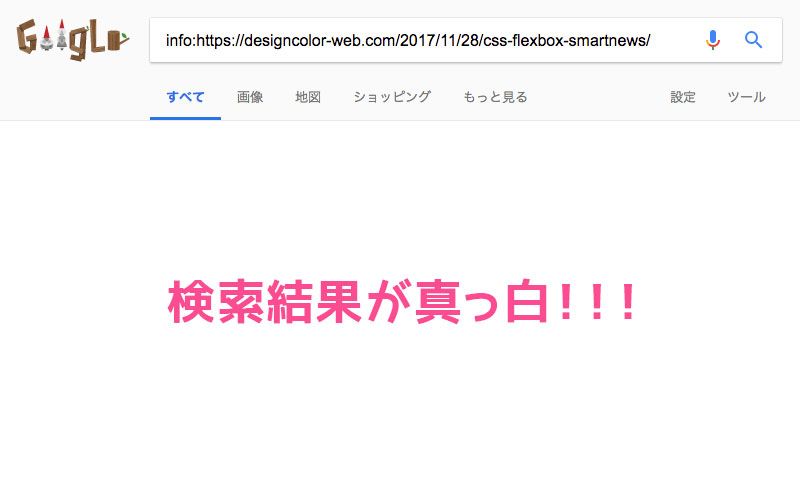
すると、何やらおかしい。検索結果に該当のURLの情報が何も表示されません。どうしてこうなったのかは不明ですが、Googleからエラーが出ていたのは恐らくこれが原因のようです。
XMLサイトマップで送信されているのに、せっかく書いた記事が検索結果に表示されていないのは問題ですね。
Fetch as Googleで再クロールしてもらおう
noindexの記述がなく、サイト側に原因がないのであれば、解決方法としては「再クロールしてもらう」という手段が挙げられます。さっそく、右サイドバーの「FETCH AS GOOGLE」をクリックしましょう。
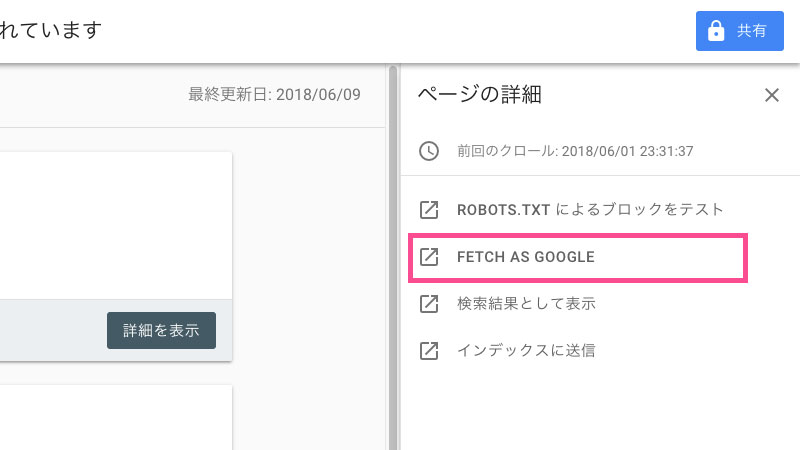
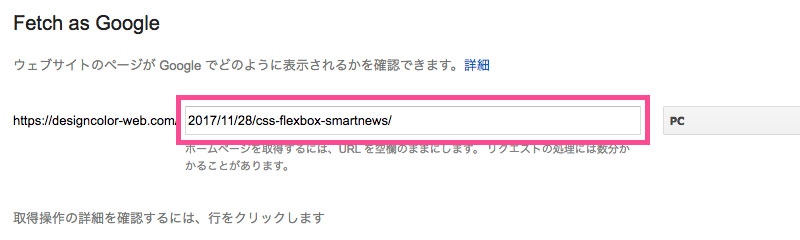
クリックするとFetch as Googleのページに飛びます。クロールしてほしいURLを入力しましょう。
プルダウンから呼び出すGooglebotの種類を選択し、「取得」をクリック。「取得してレンダリング」でもOKですが、こちらは少し時間がかかります。
「取得してレンダリング」のほうではGooglebotからの見え方とブラウザでの見え方を確認できたり、取得できなかったリソース一覧を表示してくれたりします。
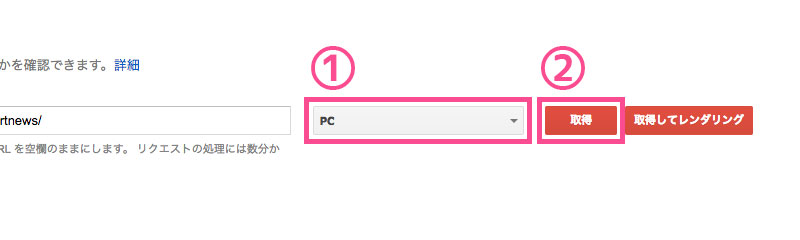
ちなみに、呼び出すGooglebotの種類は、通常は「PC」を選択するそうですが、私は一応「PC」と「モバイル:スマートフォン」両方とも取得しました。
取得が完了したら、ステータスの右側に「インデックス登録をリクエスト」というボタンが表示されるので、クリック。

ポップアップが表示されるので、「このURLのみをクロールする」を選択して送信します。(「私はロボットではありません」にチェックを入れるのをお忘れなく!)
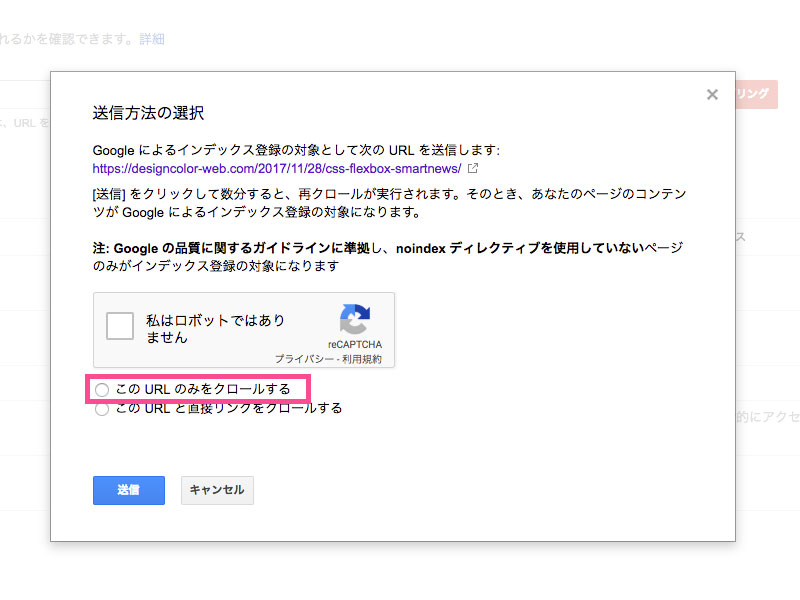
ちなみに、「このURLと直接リンクをクロールする」を選択すると、指定したURLとそのURL上に掲載されたすべてのリンクをクロールします。通常はトップページなどで利用されるそうです。
また、それぞれの送信できる数には上限があるので、早くクロールしてほしいからといって送信しすぎないよう注意しましょう。
- この URL のみをクロールする:1日につき10件まで
- このURLと直接リンクをクロールする:1日につき2件まで
インデックスされるのを待とう
インデックスを送信できたら、最後にエラー画面に戻り、「修正を検証」ボタンを押します。
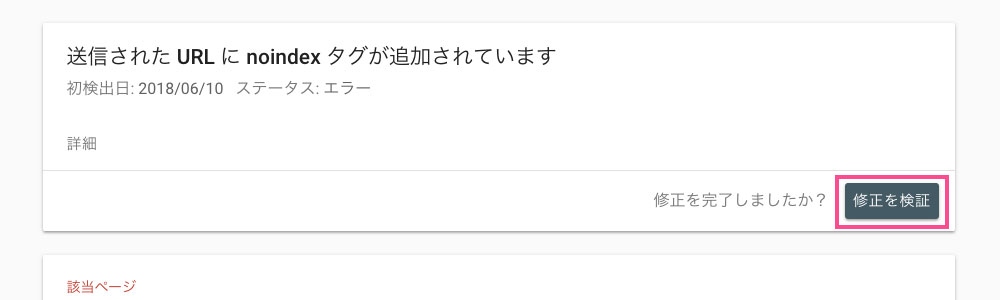
すると、ステータスが「検証:開始」になり、Googleから「『インデックス カバレッジ』の問題を検証しています」という件名のメールが届きます。
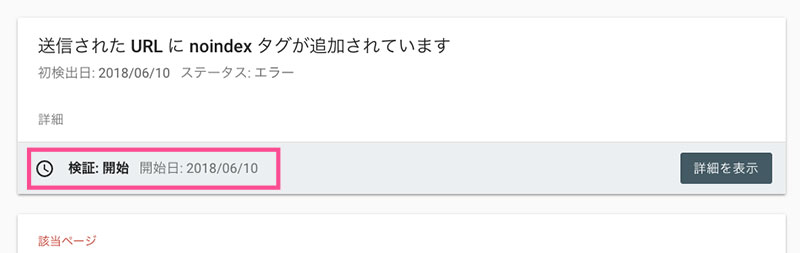
あとはもう早くクロールされてページに間違いがないことを分かってもらえることを待つのみ。
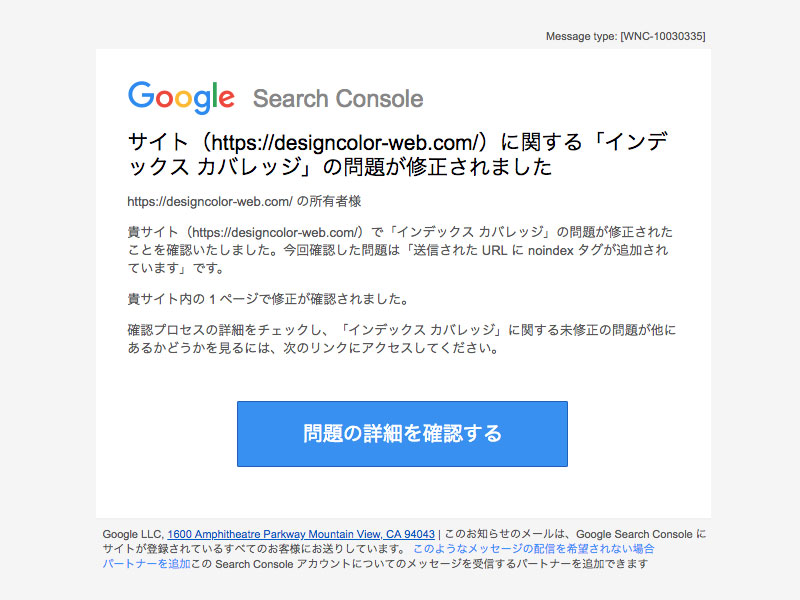
後日メールが届いたら完了
数日すると、問題が修正された旨を知らせるメールが届きます。私の場合は3日で問題が修正されたようです。やってみれば、なんてことはないんですね。
さいごに
いままでに何回かSearch Consoleのメールで飛び上がって手探りで修正してきましたが、イマイチきちんとひとつひとつ理解してこなかったので今回は勉強になりました。
もし、自分と同じようにnoindexなんかつけた覚えないけど…という人の役に立てればいいなーと思います。
以上、彩でした!




コメント